Projects
I'm always working on new projects. Find more on my GitHub.

Research Assistant & MEng Capstone — ML Engineer08/2025-Present
Berkeley Teaching AI (TAI)
- ➤ Built a hierarchical AI file reorganization agent using BFS traversal, confidence-aware semantic routing, and LLM-assisted classification, transforming unstructured course repositories into structured learning pipelines — reducing manual organization effort by ~70% and achieving 99.4% file categorization accuracy and 97.3% lecture labeling accuracy on CS 61A.
- ➤ Developed TAI-SlideQA: a multimodal slide question-answering system using VLM-augmented retrieval (CS 288 project), enabling the TAI QA agent to answer questions grounded in lecture slide images using vision-language model reasoning.
- ➤ Contributed to the open-source Berkeley TAI platform (tai.berkeley.edu) — a RAG-based AI tutoring service backed by Llama3 + BGE-M3 embeddings + sqlite-vss, enabling any Berkeley course to deploy a private natural-language AI course assistant.
- ➤ Implemented structured LLM output pipelines via Pydantic schemas and Plan-and-Solve prompting, writing reorganized logical paths back into course metadata databases for downstream retrieval.
PythonLLMVLMRAGFastAPIPydanticSQLiteLlama3NLPMultimodal
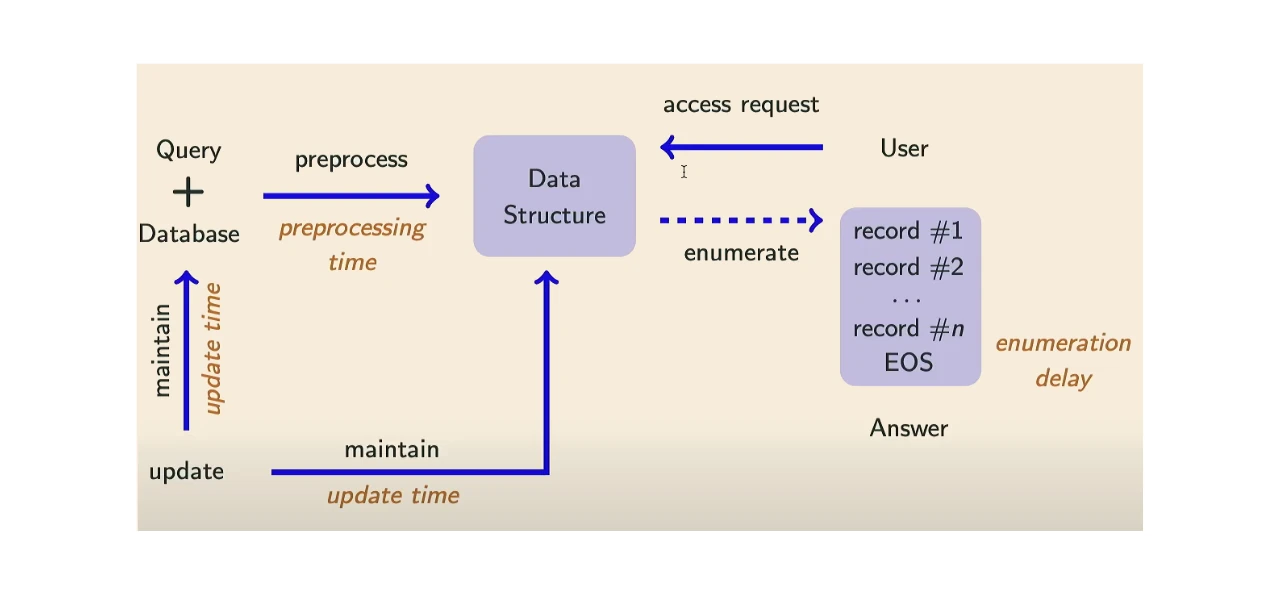
Research Assistant07/2024-Present
Matryoshka — Scalable Dataset Discovery & Feature Selection
- ➤ Co-designed Matryoshka, an ML-centric dataset discovery and feature selection system enabling scalable experimentation over 100M+ row relational data lakes without materializing full joins, using Python, PostgreSQL, and DuckDB.
- ➤ Implemented a two-phase optimizer combining table ranking with multicollinearity-aware feature pruning via proxy ML models, accelerating feature computation by 10× on datasets exceeding 100M rows through cached aggregate reuse and incremental covariance updates.
- ➤ Built automated benchmarking pipelines using Docker, Pandas, and NumPy to evaluate join strategies and discovery plans across diverse data lakes, demonstrating superior scalability and downstream ML accuracy.
- ➤ Designed custom inverted indexes and pre-computed Gram matrix sketches for scalable analytics, avoiding full materialization of joins and incrementally updating covariance statistics.
PythonDuckDBPostgreSQLDockerPandasNumPyMLFeature Selection
Coming soonProf. Babak Salimi ↗

Team Member01/2025-06/2025
Addressing Voter Turnout Disparities through Data-Driven Resource Allocation
- ➤ Stricter fairness constraints τ achieve more equitable distribution while maintaining near-optimal turnout impact.
- ➤ Fairness-constrained allocation better aligns with racial equity objectives.
- ➤ Unconstrained optimization maximizes turnout but exacerbates existing disparities.
PythonJupyterData CleaningModelingAnalysisleafletNext.jsReactTypeScript
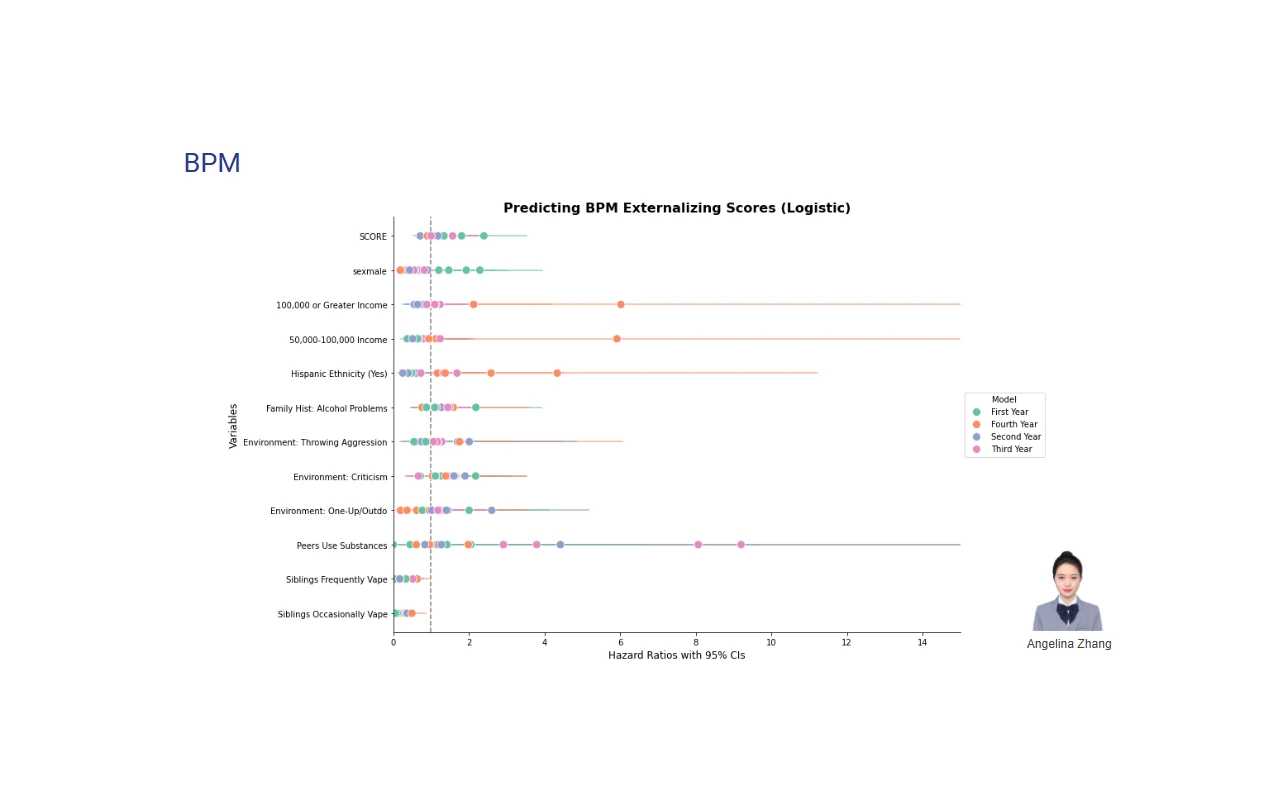
Research Assistant06/2024-04/2025
Adolescent Brain & Behavioral Genetics (ABCD Study)
- ➤ Engineered ETL pipelines to process and integrate multi-terabyte BPM and ABCD datasets into normalized schemas for longitudinal cohort studies, delivering a merged dataset to support group efforts in combining data for the final cohort.
- ➤ Trained ensemble ML models including regularized regression (Ridge, Lasso), Cox proportional hazards models for survival analysis, and bidirectional LSTMs with attention mechanisms for longitudinal trajectory prediction; achieved AUC >0.80 and R² >0.65 on held-out validation sets.
- ➤ Implemented cross-validation strategies with nested hyperparameter tuning (Optuna, GridSearchCV) and feature importance analysis (SHAP values, permutation importance) to identify top 50 predictive biomarkers for adolescent substance use.
- ➤ Built interactive dashboards using Plotly Dash, Flask, and Matplotlib, providing clinicians real-time access to statistical model outputs; conducted cross-sectional and longitudinal multivariate regression analyses.
PythonPyTorchPandasSHAPOptunaPlotlyFlaskSurvival AnalysisLSTM
Coming soonPI Profile ↗
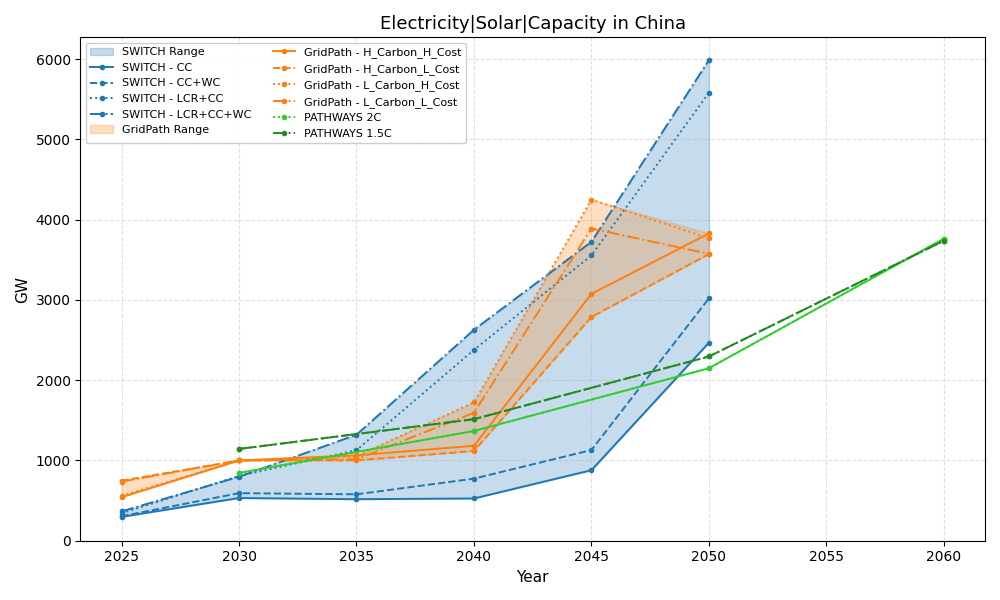
Engineering Research Assistant06/2023-09/2025
China's Electricity Market & Mid-Century Power System Review
- ➤ Built a production ML forecasting platform combining OCR, ETL, and ensemble time-series models (Prophet, XGBoost) processing 50M+ rows across 22 provinces, enabling 12-month forward electricity demand projections with 95% confidence intervals.
- ➤ Engineered a transformer-based NLP pipeline (BERT embeddings, KNN, hierarchical clustering) converting 1,000+ unstructured policy documents into 50+ quantitative regulatory features, revealing cross-province policy diffusion patterns.
- ➤ Automated ingestion of 22+ provincial energy datasets using Python (OCR, BeautifulSoup, Selenium), deployed ETL workflows on SDSC servers with Cron for continuous updates; built and maintained PostgreSQL relational schemas supporting national-scale energy modeling (>50M rows).
- ➤ Contributed to the China Mid-Century Power System Review (Jun 2025, with Michael Davidson & Zhenhua Zhang): analyzed mid-century electricity capacity scenarios across SWITCH, GridPath, and PATHWAYS models for China carbon neutrality pathway.
PythonPostgreSQLOCRETLProphetXGBoostBERTNLPData VisualizationR
Coming soonPower Transformation Lab ↗

Research Assistant06/2023-06/2024
Re-NeRF — Ultra-High-Definition NeRF with Deformable Net Alignment
- ➤ Co-developed Re-NeRF (Ultra-High-Definition NeRF with Deformable Net Alignment), optimizing high-resolution NeRF training with deformable convolution networks to resolve misalignment issues, achieving faster rendering and reduced model size without quality loss (measured by PSNR and SSIM).
- ➤ Automated evaluation pipelines and published reproducible training code, improving experiment turnaround and model benchmarking efficiency across diverse ultra-high-resolution scenes.
- ➤ Reviewed and synthesized three recent image inpainting papers, analyzing innovations in strategy, design, stability, and algorithm, and identifying failure modes to inform future research directions.
PythonPyTorchNeRFComputer VisionDeep LearningDeformable Convolution

Developer
Automated Public Equity Research Data Scraping System
- ➤ Utilized professional terms such as "free equity research reports," "analyst revenue estimates," and "future revenue estimates for public companies" to precisely locate target websites. Strictly evaluated each candidate website to ensure the data's predictive nature and breadth.
- ➤ Designed and implemented a Python web script to automate the extraction from selected websites. The script incorporated advanced error handling and retry mechanisms to ensure continuous and stable data retrieval despite network instability and server response delays.
- ➤ Developed a data cleaning and preprocessing module to standardize the format of data from different sources, ensuring consistency and accuracy. Integrated the processed data into the company's MongoDB cluster, supporting large-scale data storage and rapid querying.
PythonJupyterMongoDBJSON
Coming soon